Question du jour: How does
digg.com actually sort their articles on their frontpage?
Despite the number of digg-clones out there, I couldn't really find anything particular useful in order to reproduce their ordering (see [
1] or [
2] for example, but both did not provide any answer to my question).
Well, how about some simple reverse engineering? A couple of hourse ago I took the top 40 stories together with their
- number of diggs
- number of comments
- time in minutes since the article has been posted
Some other possible factors in the digg-algorithm, but to which i don't have access to, might be the
- number of click-throughs
- number of views
- number of non-diggs (that is a view for a registerd user, that does not digg the item)
You can download the sorted list from here:
digg (csv, 2 KB)
First some illustrative charts, and some observations (which might be obvious to regular digg-users):
R> plot(data$diggs, type="l", main="Top 40 Stories at digg.com", ylab="nr of diggs", lwd=2)
R> points(data$comments*10, typ="l", col=4)
R> legend(1, 2800, legend=c("diggs", "comments * 10"), text.col=c(1,4))
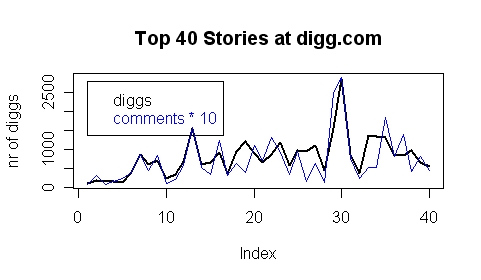
1. Stories with very very few diggs make it to the absolute top.
2. Story "30" has 6 times more diggs than story "28". Therefore i assume that the "value" of a digg decreases with each additional digg. ln(digg)?.
3. Astounishingly the number of comments per story is nearly exactly ten times the number of diggs. Therefore due to this linear dependency between diggs and comments this variable probably won't be useful for our model.
R> plot(data$time, type="l", main="Top 40 Stories at digg.com", ylab="time in minutes", lwd=2, ylim=c(0,3000))
R> points(data$diggs, col=4, cex=0.5)
R> legend(1, 2800, legend=c("time in min ", "diggs"), text.col=c(1,4))
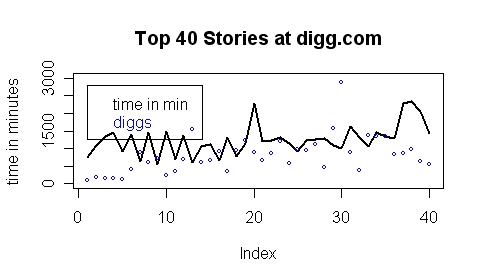
1. There is not a single story that is younger than 9 hours in this list!
2. There is not a single story that is older than 40 hours in this list.
3. This narrow bandwidth let's one assume that digg.com is using some sort of time-thresholds to enter the list.
4. Story 21 and 22 are nearly of the same age, but story 21 with 25% less diggs than story 22 is still ranked further on the top!?
5. Story 20 and 22 nearly have the same nr of diggs, but story 20 is nearly double as old as story 22, but is still ranked further on the top!? This and the previous finding
strongly indicate that there are additional variables to the model than diggs and times, but unfortunately i dont have access to them.
6. Story 21 to 40 are nicely sorted according to their age (with just a few exceptions). Maybe this is a coincedence, but it seems that age plays a more important role for the sorting of the older articles.
Then I tried to factor these findings into a simple model, and came up with the following:
rank = log(diggs) / time^2
R> plot(data$logdiggs * data$timepenalty^2, main="log(diggs) / time^2", ylab="", lwd=2, cex=1, pch=4)
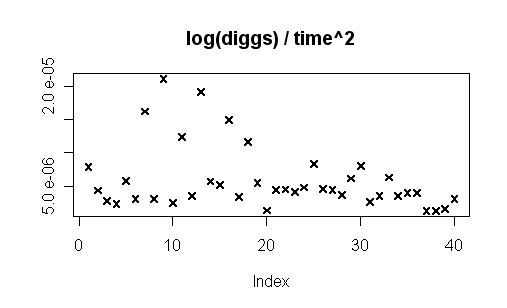
In a true model the chart above would show a strictly decreasing path. Obviously i am unable to explain why the first five/six stories made it to the top with that few diggs.
Despite that let's see how good our model actually is:
R> lm1 <- lm(log(data$score) ~ data$logdiggs + log(1/data$timepenalty^2))
R> summary(lm1)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -9.3065 1.7274 -5.388 4.24e-06 ***
data$logdiggs 0.8771 0.1032 8.502 3.14e-10 ***
log(1/data$timepenalty^2) 0.4521 0.1130 4.003 0.000289 ***
---
Signif. pres: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.4859 on 37 degrees of freedom
Multiple R-Squared: 0.7063, Adjusted R-squared: 0.6905
F-statistic: 44.5 on 2 and 37 DF, p-value: 1.429e-10
Well, it's still far away from perfect, but according to these results i am at least able to explain 69% of digg's sorting algorithm. I guess most of the remaining 31% depend on the number of non-diggs. I would highly appreciate it if anyone can point me to articles/papers that provide some further insights into digg's/reddit's/yigg's mechanism.
Maybe it's all not that complex anyways.
Update: Shame on me. Actually it is really not that complex at all, as
joshrt pointed out in the comments at
here. And obviously i am not a regular digg-user, otherwise i would have known better.
The sort order always stays the same! So, as soon as the article makes it to the frontpage, digging does not change anything? So, why should anyone digg anything on the frontpage? Just for the
topstories? Does reddit work the same way?
So the new question is:
What determines whether an article makes it to the frontpage or not? Is it really just an absolute number of diggs? Does it matter who diggs it? Do a fixed number of articles enter the frontpage within a certain timeperiod? Why do some articles take so long to make it to the frontpage? What is the alogrithm behind that?
As you can see, I am still interested in finding out how that works.

 Michi a.k.a. 'Michael Platzer' is one of the
Michi a.k.a. 'Michael Platzer' is one of the 

{kind=link}
{kind=link}